Les capacités avancées de ChatGPT, telles que la correction de code, la rédaction d'un essai ou la plaisanterie, ont contribué à sa popularité massive. Malgré ses capacités, son assistance était jusqu'à présent limitée au texte - mais cela va changer.
Le mardi, OpenAI a dévoilé GPT-4, un grand modèle multimodal qui accepte à la fois des entrées de texte et d'image et produit des sorties de texte.
Aussi : Comment rendre ChatGPT capable de fournir des sources et des citations
La distinction entre GPT-3.5 et GPT-4 sera "subtile" dans une conversation informelle. Toutefois, le nouveau modèle sera bien plus performant en termes de fiabilité, de créativité et même d'intelligence.
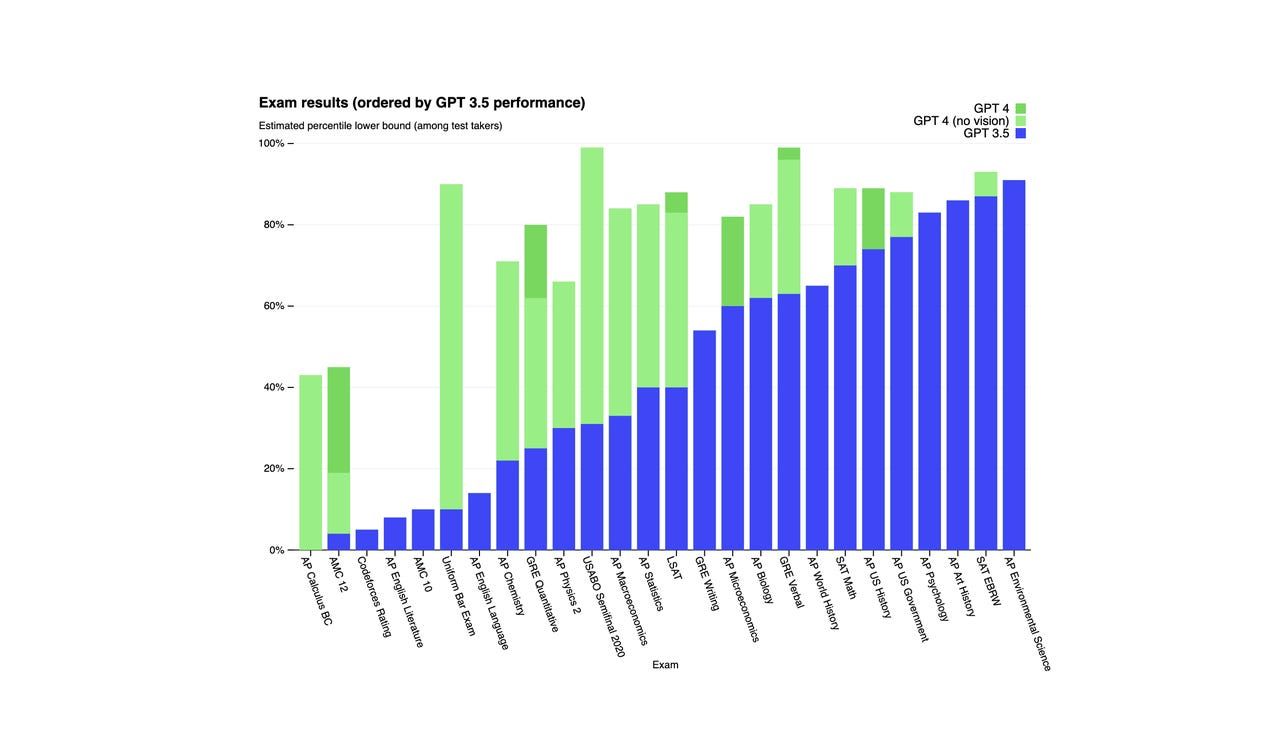
Selon OpenAI, le GPT-4 a obtenu un score parmi les 10% les plus élevés lors d'un examen de barème simulé, tandis que le GPT-3.5 a obtenu un score parmi les 10% les plus bas. Le GPT-4 a également surpassé le GPT-3.5 lors d'une série de tests de référence, comme le montre le graphique ci-dessous.

Pour information, ChatGPT s'appuie sur un modèle linguistique optimisé à partir d'un modèle de la série 3.5, ce qui limite le chatbot à la sortie de texte.
L'annonce du GPT-4 d'OpenAI a fait suite à un discours d'Andreas Braun, directeur technique de Microsoft Allemagne, la semaine dernière, dans lequel il a déclaré que le GPT-4 arriverait bientôt et permettrait la possibilité de générer du texte vers la vidéo.
Aussi : Comment fonctionne ChatGPT ?
"Nous allons présenter le GPT-4 la semaine prochaine ; nous aurons ainsi des modèles multimodaux qui offriront des possibilités complètement différentes - par exemple, des vidéos", a déclaré Braun selon Heise, un média allemand lors de l'événement.
Malgré le fait que GPT-4 soit multimodal, les affirmations concernant un générateur de texte-vidéo étaient un peu exagérées. Le modèle ne peut pas encore produire de vidéos, mais il peut accepter des entrées visuelles, ce qui constitue un changement majeur par rapport au modèle précédent.
Un des exemples fournis par OpenAI pour présenter cette fonctionnalité montre ChatGPT en train de scanner une image dans le but de comprendre ce qui rendait la photo amusante, selon l'entrée de l'utilisateur.
D'autres exemples ont inclus le téléchargement d'une image d'un graphique et demander à GPT-4 de faire des calculs à partir de celui-ci ou le téléchargement d'une feuille de calcul et lui demander de résoudre les questions.
Aussi : 5 façons dont ChatGPT peut vous aider à rédiger une dissertation
OpenAI annonce qu'il va sortir la fonctionnalité d'entrée de texte de GPT-4 via ChatGPT et son API via une liste d'attente. Vous devrez attendre un peu plus longtemps pour la fonctionnalité d'entrée d'image, car OpenAI collabore avec un seul partenaire pour la démarrer.
Si vous êtes déçu de ne pas avoir de générateur texte-vidéo, ne vous inquiétez pas, ce n'est pas un concept complètement nouveau. Les géants de la technologie tels que Meta et Google ont déjà des modèles en cours de développement. Meta a Make-A-Video et Google a Imagen Video, qui utilisent tous deux l'IA pour produire des vidéos à partir de l'entrée de l'utilisateur.